Text and voice streams are loaded with customer feedback, legal contracts, billing logs, and support requests. We build semantic indexes and tokenizer pipelines to parse, translate, and classify language structures automatically.
Our conversational agents use custom-trained transformer architectures. By applying post-training weight quantization and parameter pruning models, we trim execution context sizes. This allows models to run on localized hardware with zero latency and minimal electricity draw, ensuring that private conversations remain within your corporate network borders.
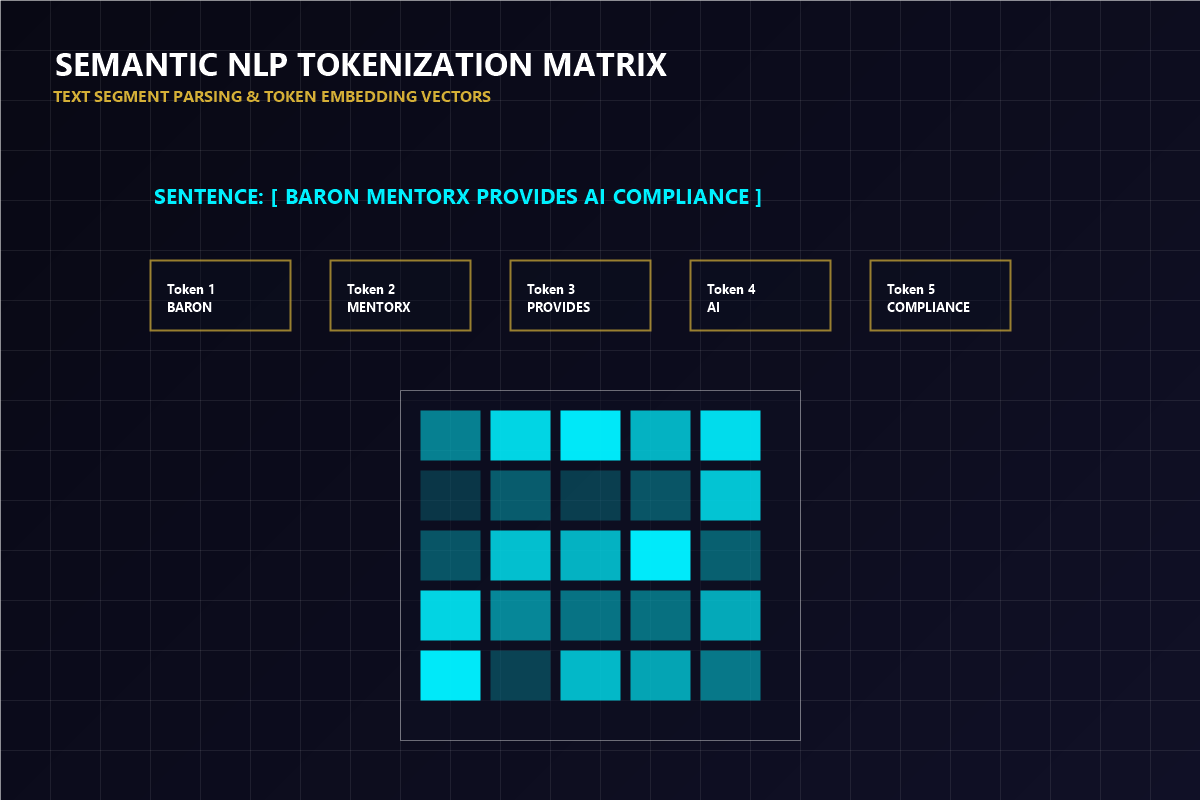
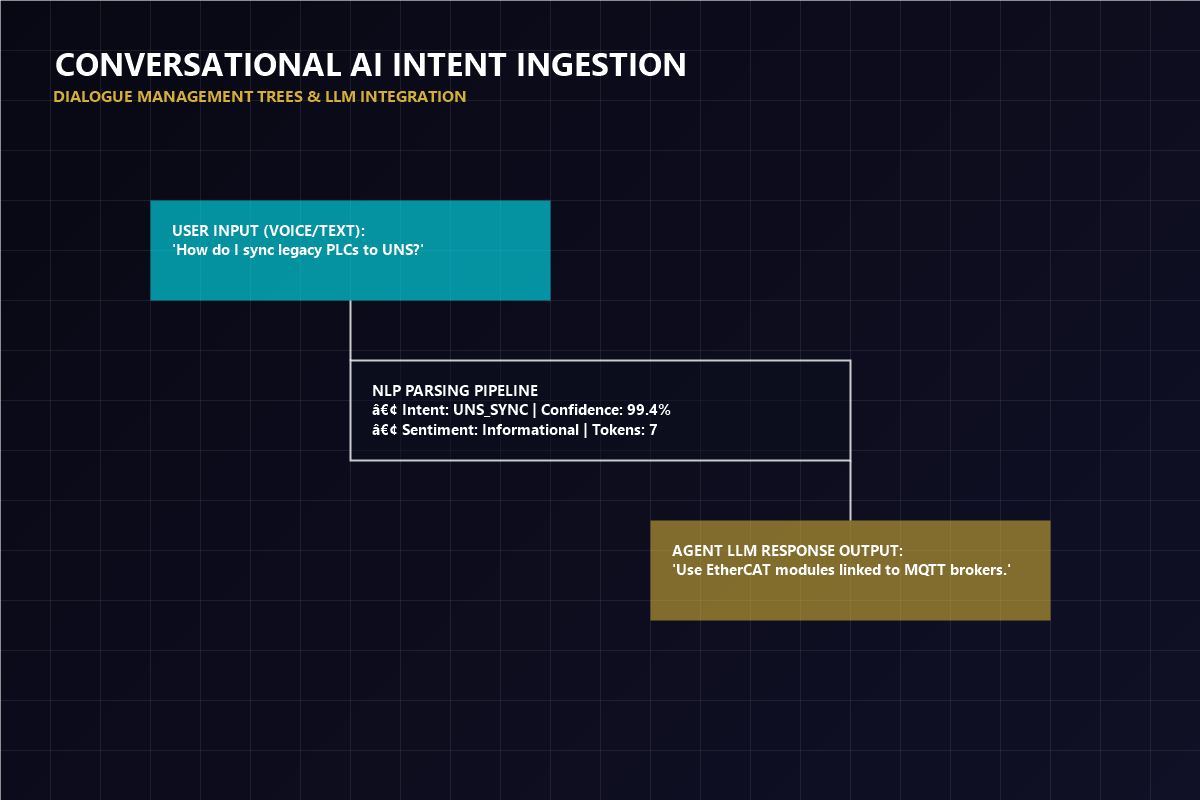
Converting raw human speech and text into logical commands requires structured parsing and semantic alignment.
Splitting sentence strings into semantic token parts, indexing punctuation and word positions for grammatical analysis.
Mapping token segments to multi-dimensional vector matrices, tracking semantic weights to determine contextual meaning.
Evaluating vectors using neural classifiers to map token strings to logical business intents and database actions.
Passing categorized intents to localized LLM weights, generating natural agent replies, and committing actions.
We build compressed transformer models with high attention memory windows.
Engineering long-context models that preserve details across multi-page document folders easily.
Storing sentence embeddings inside vector indices to facilitate fast semantic queries in real time.
Removing redundant phrasing prior to model processing, speeding execution while cutting compute emissions.
Scraping structural paperwork dynamically to extract dates, names, and amounts directly into relational records.
Deploying custom multi-head attention weights to capture relationships between non-adjacent words in dense texts.
Processing incoming voice waveforms, mapping phonetic segments to text tokens with high translation robustness.
Speak with our conversational AI architects to design secure, context-aware translation and chat tools.
Connect with NLP Specialists