Data is only valuable if it is readable, structured, and actionable. Baron MentorX helps global enterprises organize massive operational records and build custom machine learning models to unlock deep predictive value.
From designing large-scale neural network weights to deploying secure data pipeline architectures, our engineers optimize compute schedules, eliminate processing redundancies, and construct low-overhead streaming layers. This allows organizations to run continuous intelligence queries while reducing cloud computing costs and aligning with environmental sustainability mandates.
Forecast market trends, trace asset decay, and optimize logistics logs.
Supervised classifiers, reinforcement loops, and deep vision models.
Distributed stream lakes, data cleansing, and clustered databases.
Automated interactive dashboards, reporting matrix files, and KPIs.
Extracting value from raw data lakes demands a structured, failsafe, and scalable integration process.
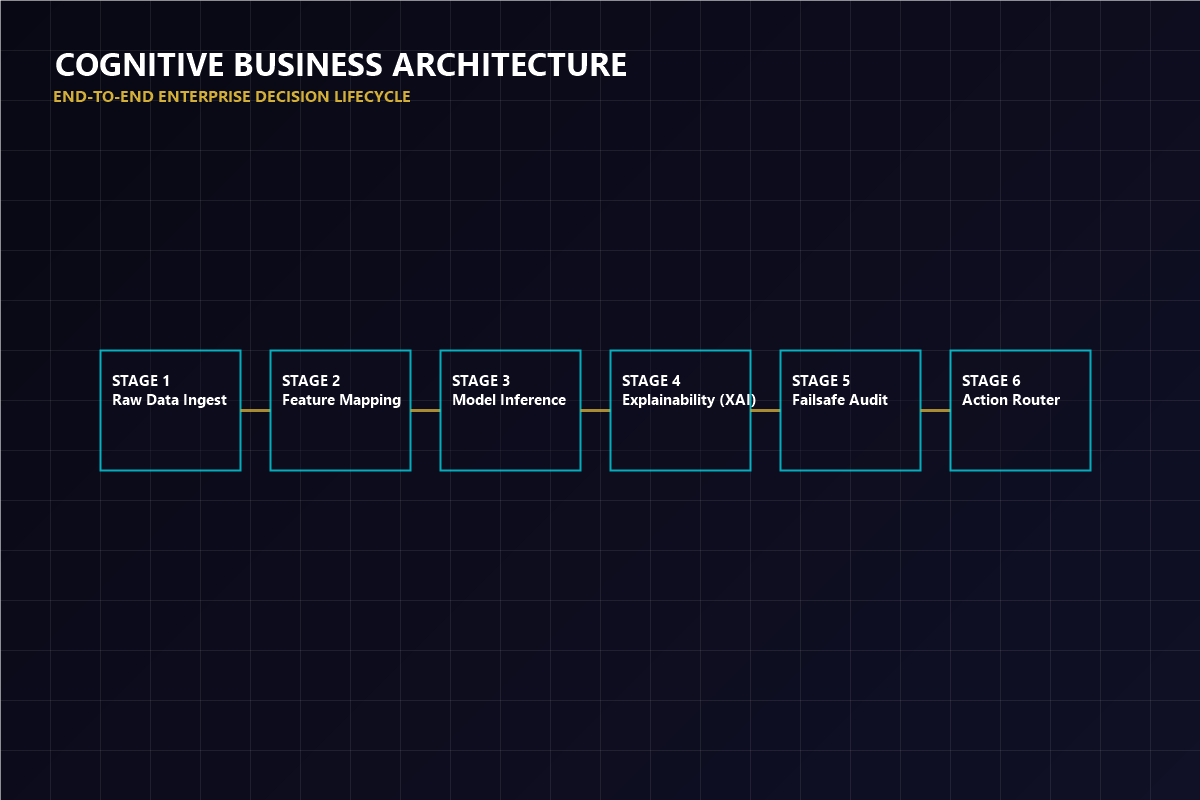
Deploying event brokers to capture raw log inputs, checking schema compliance dynamically to prevent corrupted records from infiltrating databases.
Extracting feature vectors, tuning parameters, and training custom neural network weights on high-capacity GPU cluster compute units.
Auditing loss functions to detect and mitigate demographic biases, and generating local explainability records to justify outputs to inspectors.
Packaging finalized classifiers into lightweight docker nodes, connecting them to active PLC buses or API routers to execute decisions in under 10ms.
We combine high-capacity data engineering with low-latency execution frameworks to guarantee secure, high-uptime operations.
Our data streams process millions of records in sub-milliseconds, triggering automated decisions without database write latency.
By compressing parameter blocks and pruning neural architectures, we reduce database query power requirements by up to 35%.
We build custom, isolated memory partitions ensuring that data models never leak proprietary IP outer boundaries during training.
Updating predictive parameters across local edge points dynamically, bypassing the risk of centralized data storage hacks.
Continuous mapping of inputs to regulatory logs, maintaining compliance audits for the EU AI Act and SEC requirements.
Using Apache Kafka and MQTT clustering to link database events immediately to model nodes, eliminating query queue delays.
Speak with our lead algorithm architects to see how custom neural models can improve your organizational processing speed.
Connect with AI Engineers