In modern business ecosystems, operational data accumulates in gigabytes per minute. We engineer distributed streaming databases to capture, sanitize, and store high-throughput enterprise logs in real-time.
Our database architectures support high read/write volumes under strict execution limits. By restructuring query indexing algorithms and deploying partitioned data sharding maps, we significantly decrease server drive wear and grid power draw. This allows companies to process petabyte-scale analytics jobs on compact, green cloud compute allocations while maintaining high availability.
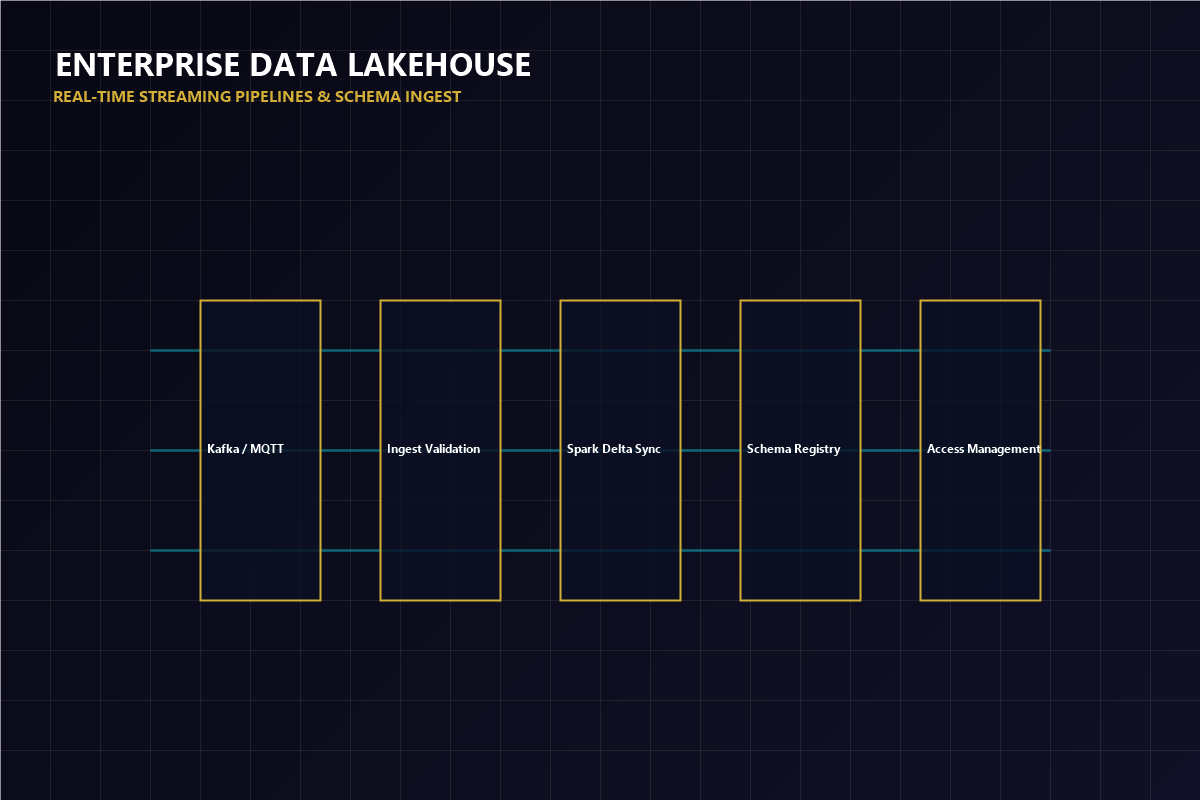
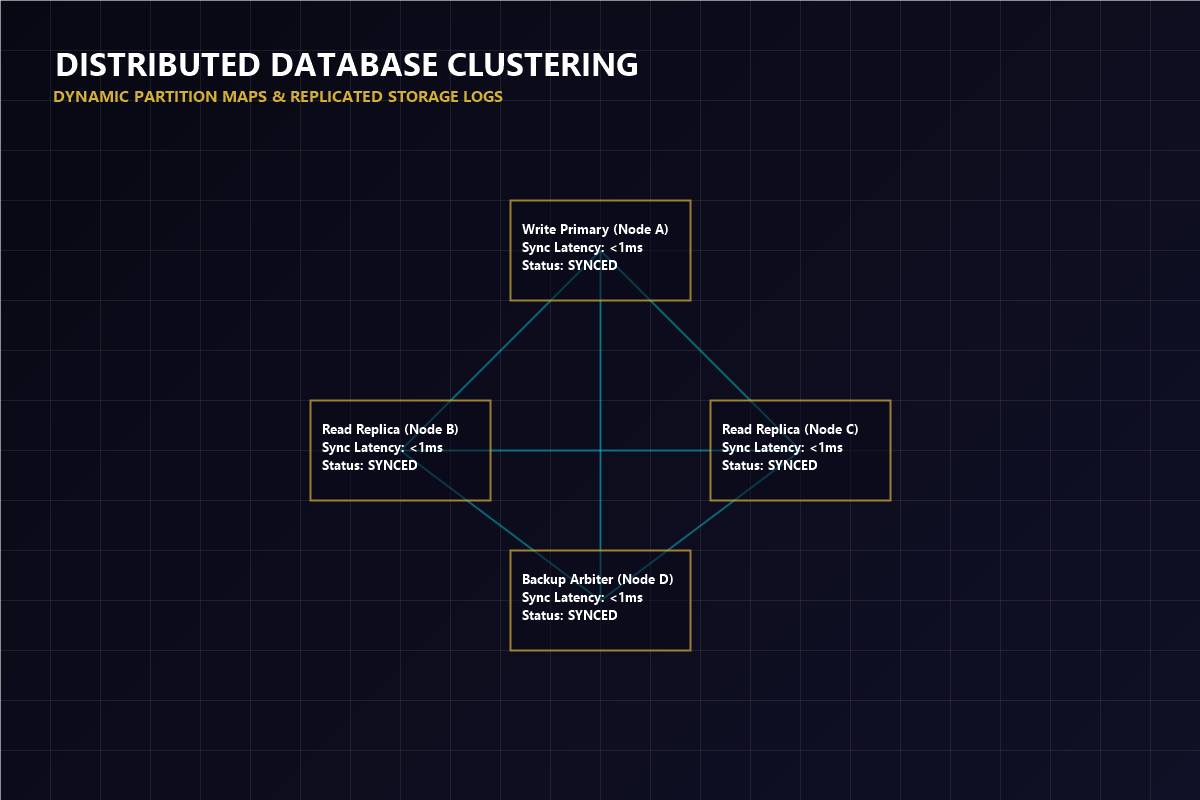
Orchestrating petabyte-scale data flows requires robust cluster node replication and strict partitioning policies.
Wiring Apache Kafka or MQTT message buffers to ingest high-frequency transaction event records from global database portals.
Splitting incoming database tables into partitioned blocks, distributing read/write loads evenly to avoid single-node performance bottlenecks.
Synchronizing replicated nodes using cluster consensus protocols, ensuring zero data loss and maintaining sub-millisecond sync latencies.
Running continuous schema checks before executing database commits, compressing logs into delta-lakehouses.
We build high-capacity clustered databases with built-in replication controls to handle transactional spikes safely.
Dividing databases into logical segments, shortening read/write execution times across networks.
Deploying auto-scaling cloud databases that handle unexpected user traffic spikes safely.
Engineering automated audit schedules that restrict access permission locks to secure private data.
Building delta-lake architectures to query raw unstructured files directly without expensive ETL staging queues.
Replicating database partition maps across server networks using consensus to ensure continuous data availability.
Deploying automated schema registry checks to detect and quarantine malformed entries at pipeline boundaries.
Speak with our cloud database engineers to structure efficient, high-performance data streams.
Connect with Database Architects